Create an ETL step to prepare your data

- The input datasource can be of any type (a SQL table, a Storage, a file...).
- The output datasource is always a Serenytics storage (i.e. a Redshift table).
- The transformation can use aggregation, filtering, selecting columns or Serenytics formulas.
If you are used to SQL, an ETL step is similar to an SQL query that you apply to a given table and you store the query result in another table.
In Serenytics, an ETL step is an "automation" object as it can be scheduled. In many projects, ETL steps are required to prepare the data before showing it in widgets such as barcharts or tables in dashboards.
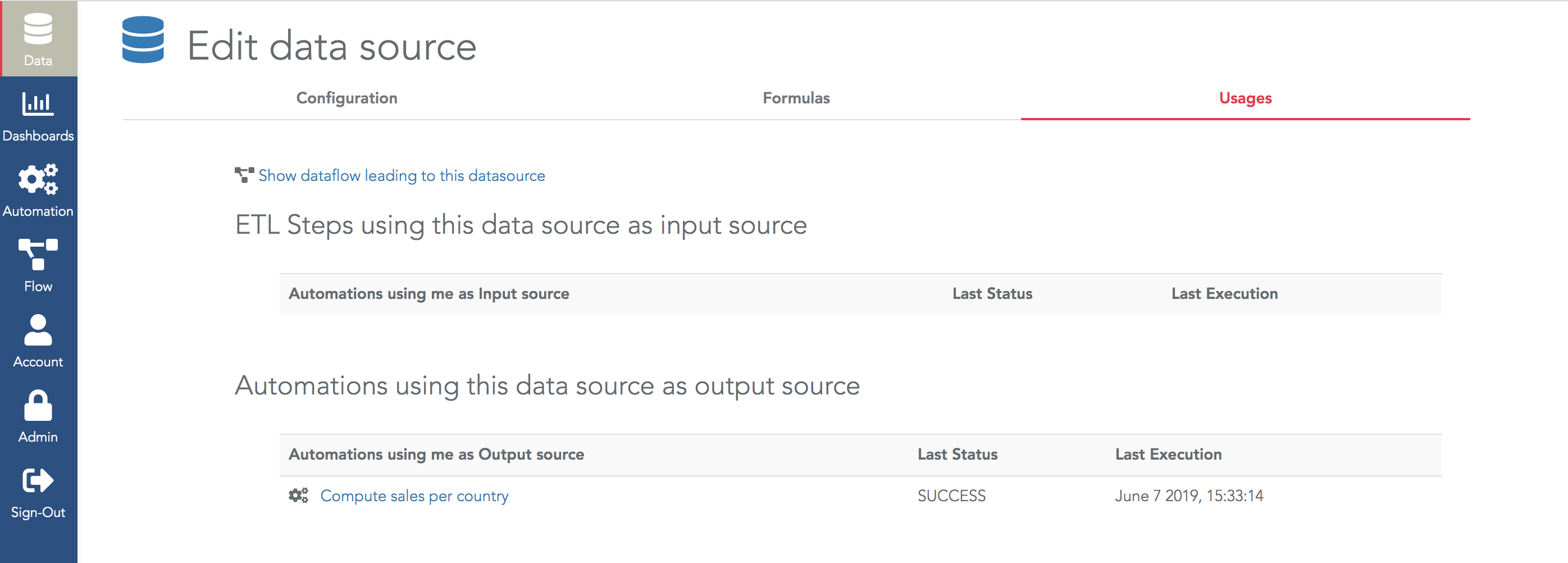
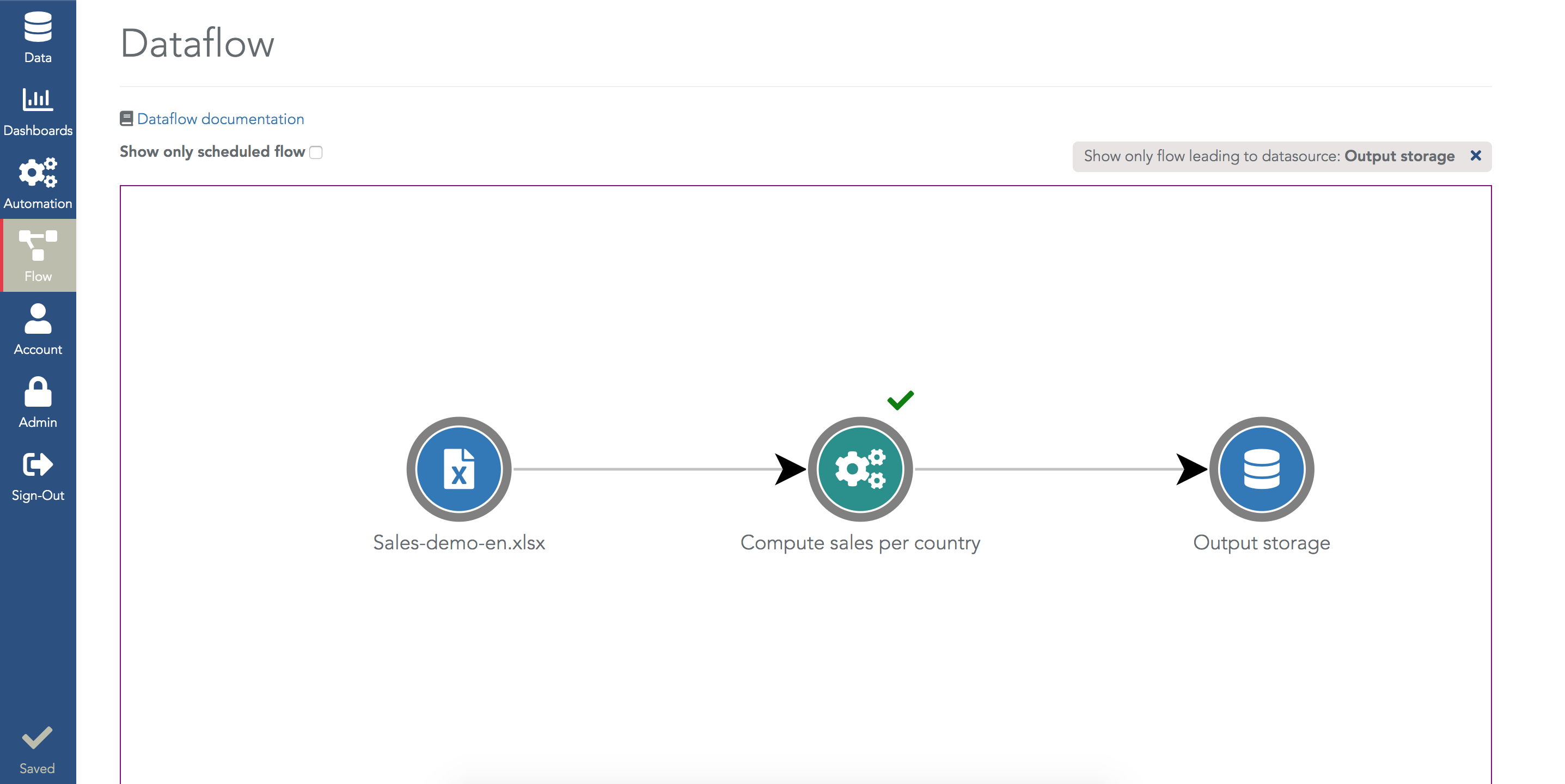
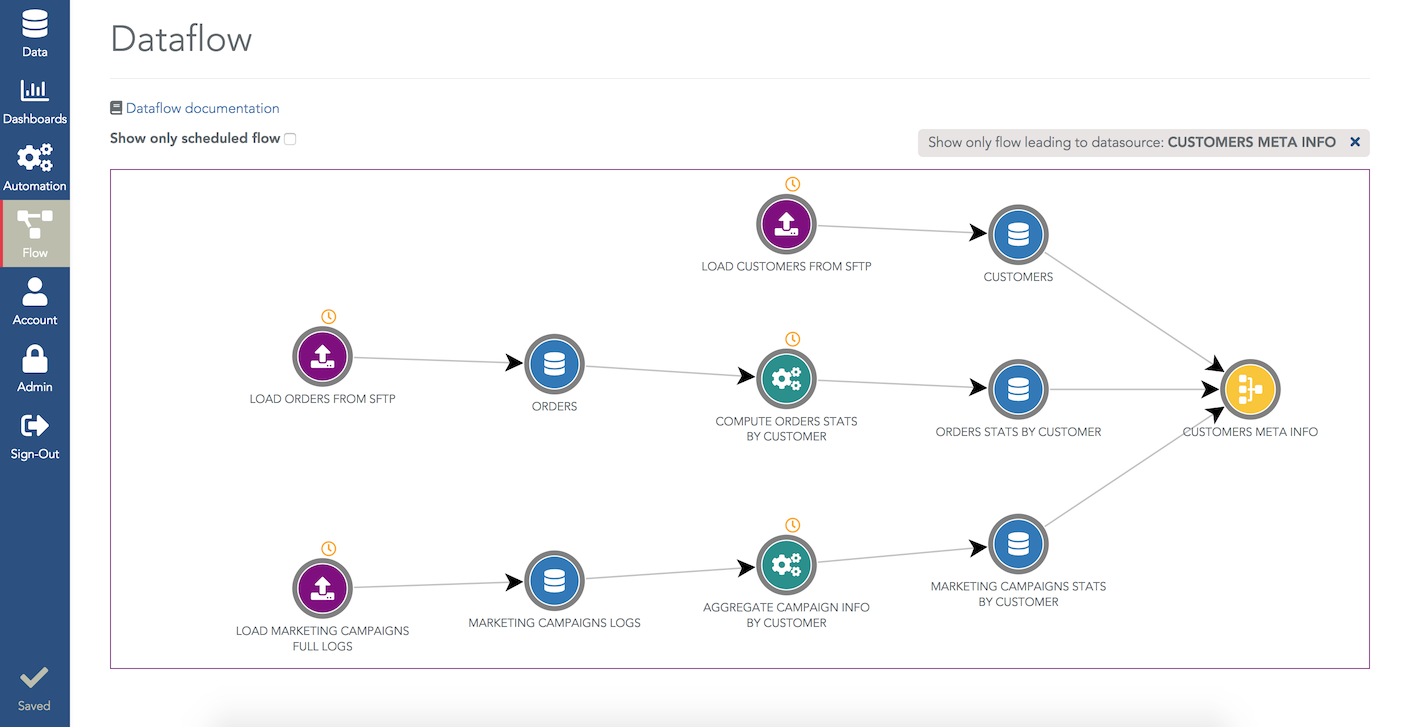
Once you have created several ETL steps, the dataflow menu lets you visualize these data preparation steps (ETL steps, and also all the data loadings steps and Python scripts):
The next step is to actually define the query applied to the input datasource. In the "Data" section, configure the "groupBy dimensions" and the "Measures".
In both fields, you'll find the list of columns available in the datasource plus the list of formulas you added in the datasource.
As soon as you modify these fields, the data preview will show you a preview of the result (keep in mind it's only a preview, the output storage has not been filled yet):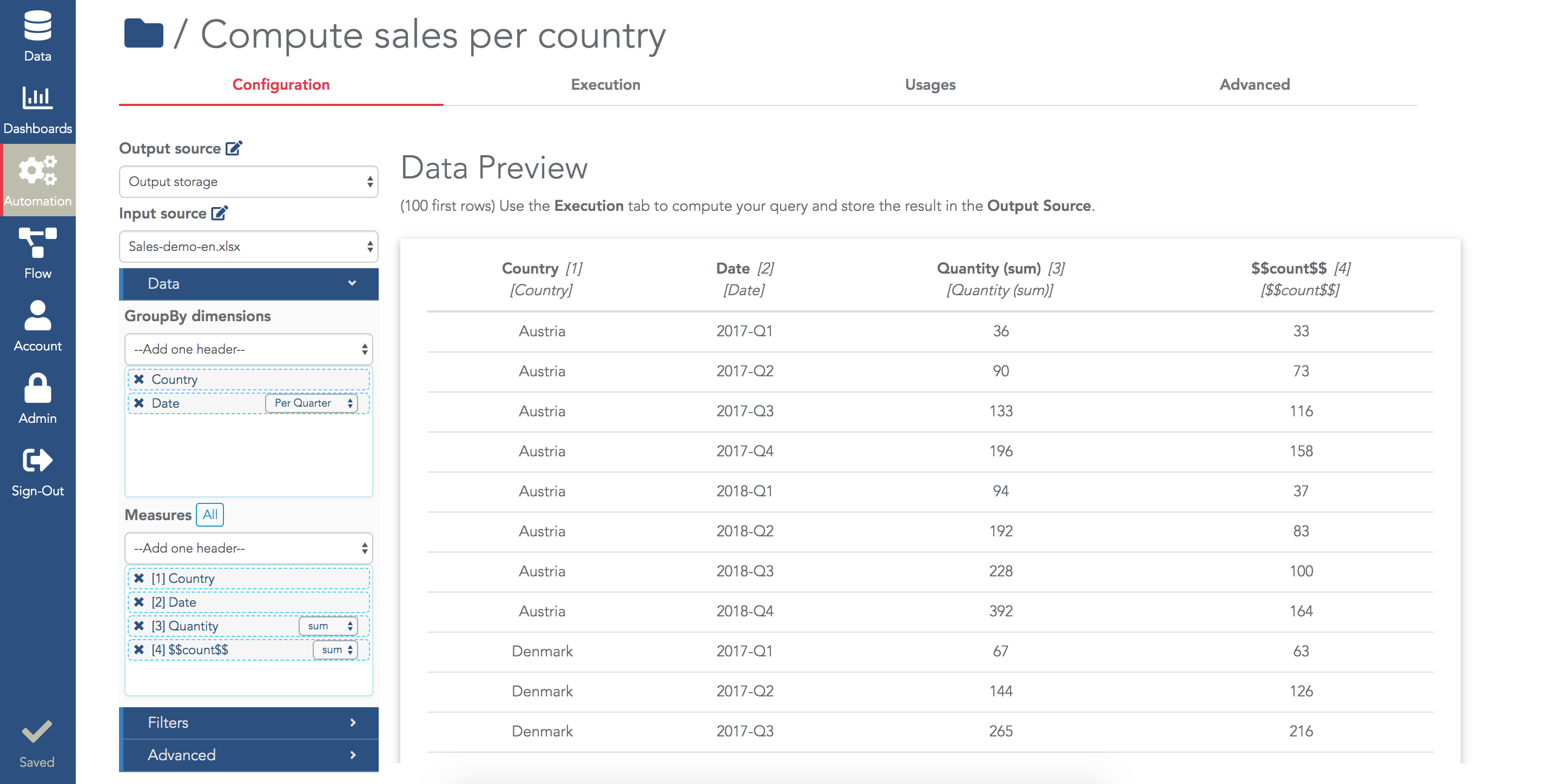
When the configuration is valid, the preview shows the first 100 rows of the result. It's important to keep in mind that the result has not been stored in the output storage so far.
You need to "execute" your ETL step: in the tab "Execution", click on "Execute Now". Your execution is triggered and when the ETL step execution is finished, you'll see a new row in the "Last 10 Executions" table:
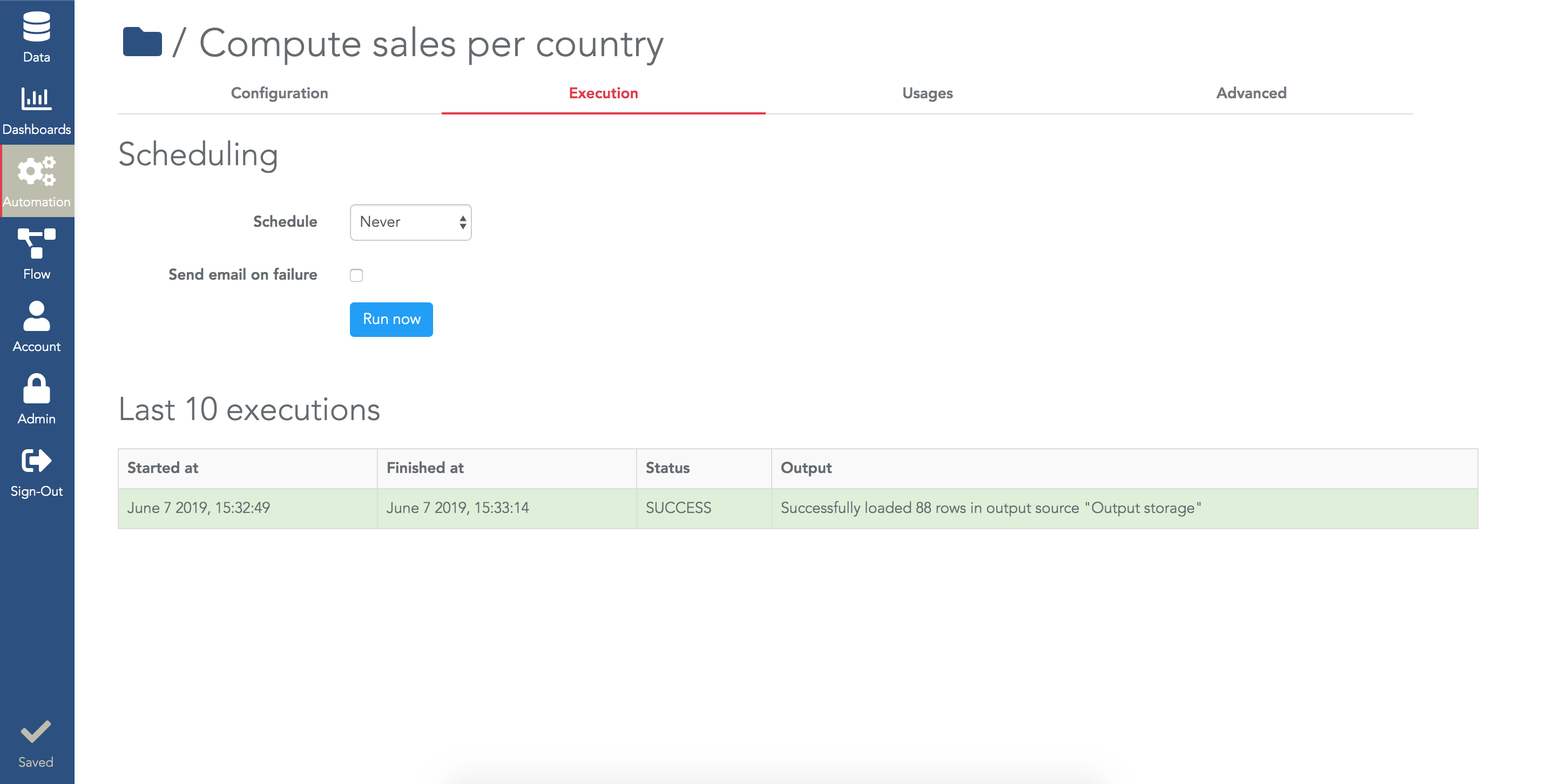
Of course, you can use the scheduling field to schedule your ETL step (e.g. to run it once a day).
A common way to manage the execution of multiple ETL steps is to have them in a "chain task" that will execute several ETL steps one after the other. And instead of scheduling each ETL step, you only schedule the "chain task" (see the dedicated tutorial).
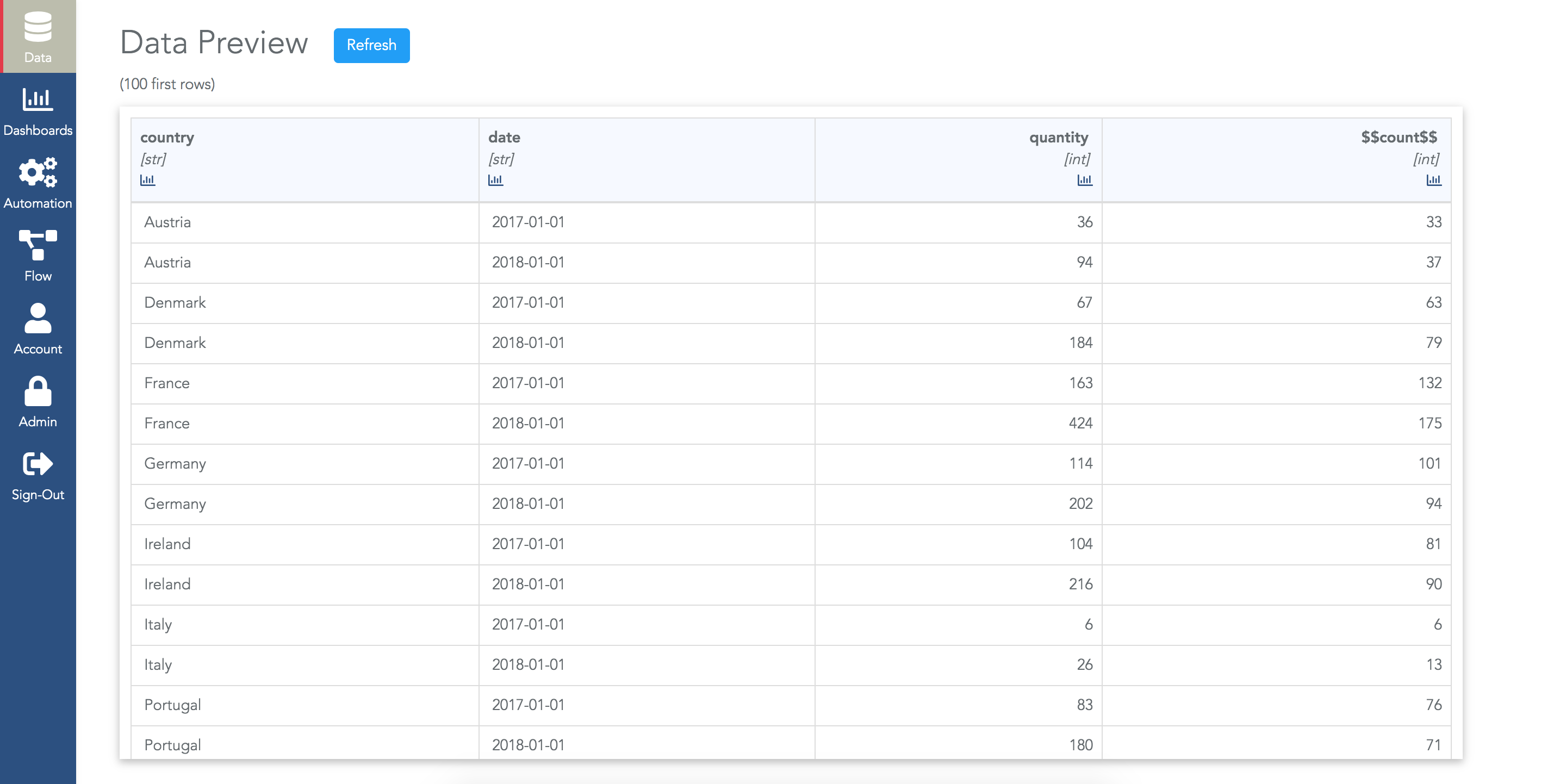
The column names are the default ones. In many situations, you'll want to rename these names.
For example, the $$count$$ column can be renamed "Nb of invoices" in the example of this tutorial. To do that, in the configuration of the ETL step, click on the header of a column in the preview and enter the new name of the column:
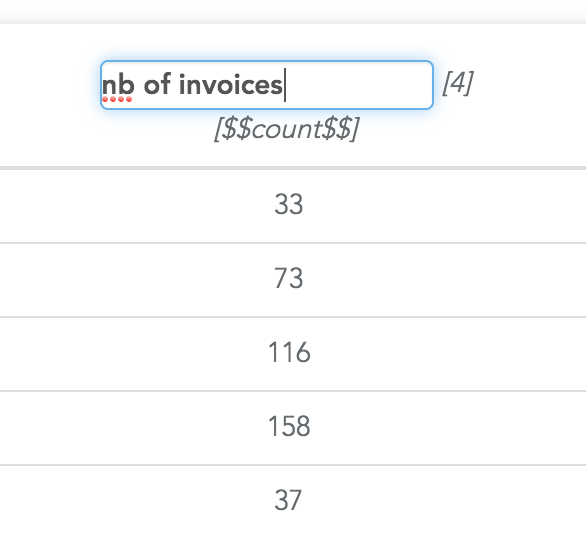
The text right below the edited name is the default name. The number right beside the column helps you to find it in the list of selected measures in the ETL step settings (it is helpful when there are many columns).
Of course, to have the columns renamed in the output storage, you'll need to execute again the ETL step.