The Serenytics data platform architecture
Back to Tutorials

Overview
Serenytics is a cloud app to manipulate data and create dashboards. The data to display in a dashboard can be obtained:
- From a data-warehouse provided by Serenytics (usually an AWS Redshift cluster). Data can be loaded in this data-warehouse using our internal ETL functions.
- Directly from any external SQL database (i.e. a customer SQL database) or from any API (e.g. a REST API, the Google Analytics API).
- From a file loaded in Serenytics.
The architecture is composed of three main modules:
- The Backend, responsible for providing the Serenytics REST API
- The Frontend, a webapp to connect datasources, create/view dashboards, create dataflows... It's an advanced client for our REST API.
- The Python client, a library to simplify the use of our API in Python.
Backend architecture
Here is the schema of our backend architecture (click to enlarge):
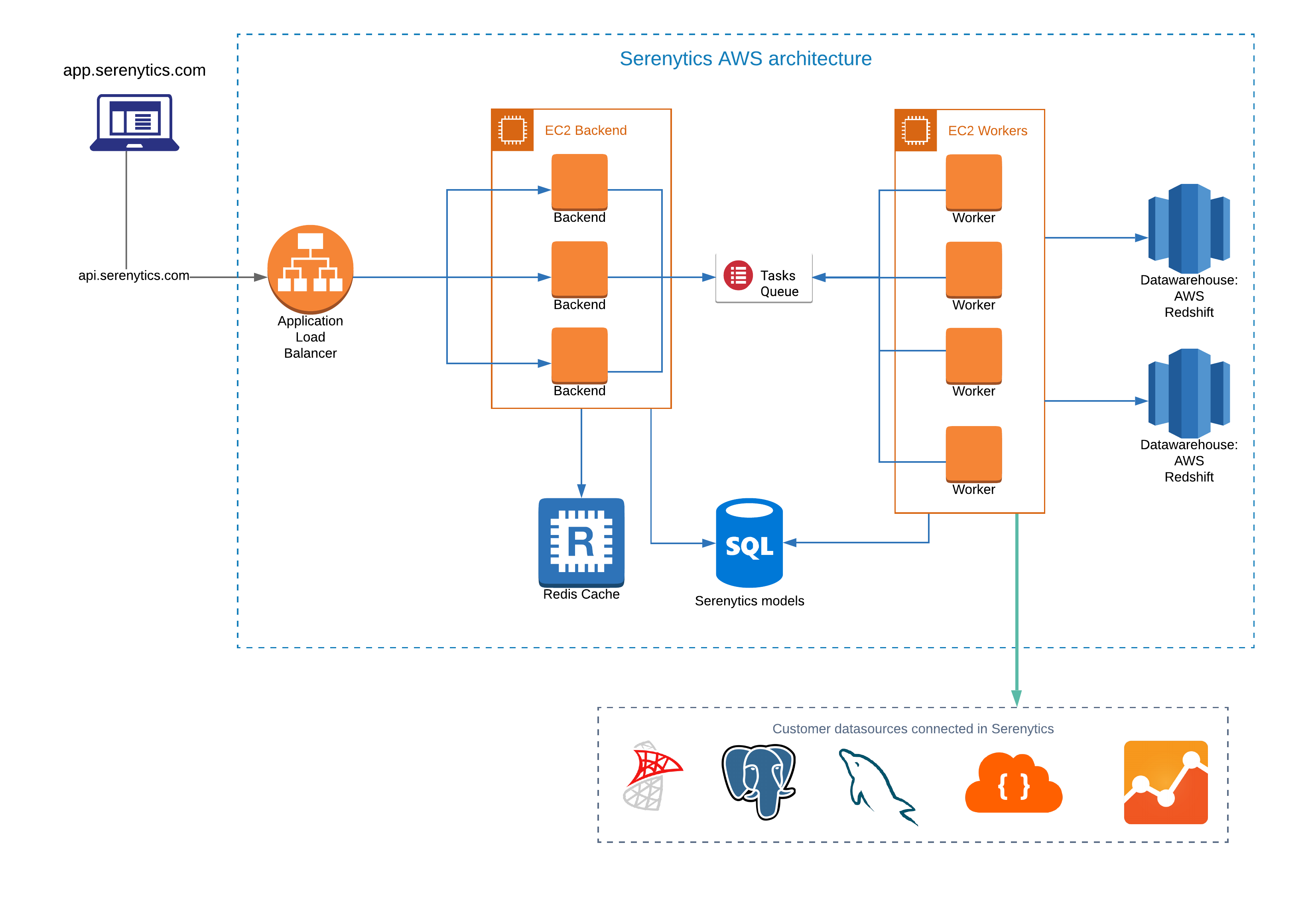
Our backend is written in Python. It uses a queue-worker architecture:
- A web server receives the request sent to api.serenytics.com. For small requests (e.g. authentification, get my list of dashboards...), it answers itself. For larger requests (e.g. query data in a datasource, generate a PDF...), it just creates a task in the queue.
- Workers compute tasks put in the queue.
- The web server uses the Flask framework, served with Gunicorn.
- Models are stored in a PostGreSQL database (we use JSON fields to store complex fields such as dashboard models).
- It uses MRQ for queuing, a distributed task queue built on top of MongoDB, Redis and Gevent.
- There is a cache system using a Redis database. For example, if a data query (e.g. "group sales, nb_items by country") has already been computed and is still valid, the web server will reply with this data instead of creating a task in the queue to compute the data query on the data-source (e.g. a SQL database).
- The most common task is to query a datasource connected by the user (e.g. a SQL database). For such a request, the web server has queued a job with the query details as parameters in JSON format (e.g. {'groupby':['country'], metrics:['sales', 'nb_items']}). The first job of the worker is to transform this JSON in a query understandable by the queried datasource (e.g. in SQL if the datasource is a SQL database). And then, it actually runs the generated query (e.g. the SQL query), waits for it to be executed and returns the results. This is mostly based on the SQLAlchemy library.
- One particular task is the Python script (i.e. the user has written Python code directly in Serenytics). For such a task, the worker executes the Python code in a dedicated Docker container.
- Some tasks can be very short (a few milliseconds), and some others may last for dozens of minutes.
- In the worker, translating a JSON to a SQL query is not trivial. Especially when the input JSON contains formulas defined on the datasource. And that would be nice if SQL databases spoke the same language, but they don't (PostGreSQL SQL is close to MySQL SQL, but it's not exactly identical).
- Serenytics is multi-tenant, meaning that some resources are shared among users (such as workers and data-warehouses). The web server has a policy to avoid allocating all the resources to a single user.
- Data queries are cancelable (e.g. if their result is not required anymore by the client). For example, if a user opens a dashboard tab and this triggers very long queries on the Redshift data-warehouse, but after a short time, he opens another tab, we cancel the queries for the first tab to run as soon as possible the queries from the new tab.
- In the web server, the choice to read a result in the cache or to compute it depends on many parameters that could invalidate the cache.
Frontend architecture
The Frontend architecture is a React/Redux application. It is mostly a CRUD (create/read/update/delete) application on the objects managed by Serenytics:
- Datasources
- Dashboards
- Sheduled tasks
Python client
The Python client is a simple wrapper around the Serenytics API. It is a lot simpler to use it rather than directly calling the Serenytics REST API. It provides high-level functions such as:
- Send an email with a dashboard attached as a PDF.
- Get data from a datasource in a Pandas dataframe.
- Trigger another Serenytics script.
- ...
Serenytics Continuous Integration
We use a classic master-featureOnBranch git model on gitHub. Each commit trigger an integration flow based on Buildkite.
The steps of this flow are :
- Run the linters (to avoid long fights on code formatting, we use Black for our Python code and prettier for the TS/JS code).
- Build backend and frontend Docker containers
- Run backend tests (based on PyTest). We have a lot of tests to check our formula engine. This part is actually coded using TDD as it is very easy to write a new formula and its wanted output, and then the developer only has to fix the tests for all the database types.
- Run frontend tests (mostly e2e tests as we think it optimizes the maintenance/coverage ratio, and we're a small team).
- We use Cypress as our test framework. Good points of Cypress are: tests are in git (so they are linked to a branch); it runs locally (without effort). The bad point of Cypress is that some tests are tricky to implement. But we have created our library of helpers (related to our features, e.g. filters in dashboards) and it's now very fast to add a new test.
- We use Percy to do a lot of visual tests. We have a large database of 'tests' dashboards. The tests ensure that the visual outputs of these dashboards do not change.
- We use Mailslurp to check emails. For example, we check that a dashboard generated in PDF and sent by email is received and its content is correct (with a simple PDF parser to extract the KPIs of the dashboard).
- Run the python client test.
- We have a dedicated module to test the corner cases of our API (e.g. query cancellation, timeouts, task chaining...).
- Publish our Python client on PyPy.
- Publish our docker images on DockerHub.
One issue with our integration pipeline is that it takes too much time (around 45 minutes). But because of shared resources behind the scene (e.g. a Redshift cluster, several SQL servers), it's not trivial to add parallelism (we've already done the low-hanging fruits). Having such a long build time is an issue as it forces developers to focus on something else during a build. And it's very frustrating when you're build fails after 40 minutes (especially if it already happened to you several times during the day).
Serenytics Deployment
Our modules are dockerized and this makes deployment very easy. The containers to deploy are:
- Backend web servers
- Workers
- Frontends (to serve it through a NGinx server)
- A PostGreSQL database for models.
- One or several data-warehouses (AWS Redshift or a PostGreSQL).
- A Redis (for queuing and cache engine).
- A MongoDB (for queuing).
- A file storage system (we use AWS S3 but it's also compatible with a local storage).
We also deploy on our local machines for development (in this case, we also have Docker containers providing all the required services such as the PostGreSQL db, Redis, MongoDB...).
Our containers are orchestrated with simple docker-compose files. We had a period running Kubernetes. It went well (it's very easy to setup). But it failed one day in prod and it took us several hours to understand the issue and fix it. This day, we realized being an expert in Kubernetes require time/resource that we don't have. So we went back to a simpler solution which is perfectly fine for our needs.
Dev setup
We mostly use PyCharm and WebStorm as IDEs.
We also use Docker containers locally. With a single command, a developer gets and runs all the containers required by the platform.
Pycharm is configured to run/debug the Python code within the backend container (so any developer runs its code in the same exact config as other devs, and exactly as in the prod env). Because asynchronous code is sometimes tedious (especially for debugging), we have an option in the backend to disable it and to run all the backend tasks without queuing.
For the frontend, the React/Redux single-way architecture coupled with a Redux live inspector helps a lot to fix bugs. Especially compared to old two-ways bindings apps in AngularJS which were impossible to scale.
Conclusion
I hope you enjoyed this deep overview of our architecture and how we work !
If you are curious about some detail, or just want to give us any feedback (or just let us know that you reached this conclusion, congrats !! ), we would love to hear from you: contact@serenytics.com.
×![]()